Combinar fuentes de datos
Contents
Combinar fuentes de datos#
En las bases de datos relacionales, combinar tablas es una de las tareas más comunes y necesarias. Por lo general, la información se divide para hacerla más fácil de gestionar y por ello al recuperarla necesitamos combinarlas para obtener un resultado coherente en una sola tabla.
Para este ejercicio necesitaremos dos fuentes de datos, así que aprovecharé el “Catálogo Único de Claves de Áreas Geoestadísticas Estatales, Municipales y Localidades” que proveé el INEGI para obtener las coordenadas geográficas de los municipios que se anotan en el conjunto de datos por Covid.
import pandas as pd
ruta_areas_inegi = '../data/AGEEML_2022842026272.csv'
areas_inegi = pd.read_csv(ruta_areas_inegi)
print(areas_inegi.shape)
areas_inegi.head()
(300083, 19)
| Mapa | Cve_Ent | Nom_Ent | Nom_Abr | Cve_Mun | Nom_Mun | Cve_Loc | Nom_Loc | Ámbito | Latitud | Longitud | Lat_Decimal | Lon_Decimal | Altitud | Cve_Carta | Pob_Total | Pob_Masculina | Pob_Femenina | Total De Viviendas Habitadas | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 10010001 | 1 | Aguascalientes | Ags. | 1 | Aguascalientes | 1 | Aguascalientes | U | 21°52´47.362N" | 102°17´45.768W" | 21.879823 | -102.296047 | 1878 | F13D19 | 863893 | 419168 | 444725 | 246259 |
| 1 | 10010094 | 1 | Aguascalientes | Ags. | 1 | Aguascalientes | 94 | Granja Adelita | R | 21°52´18.749N" | 102°22´24.710W" | 21.871875 | -102.373531 | 1901 | F13D18 | 5 | * | * | 2 |
| 2 | 10010096 | 1 | Aguascalientes | Ags. | 1 | Aguascalientes | 96 | Agua Azul | R | 21°53´01.522N" | 102°21´25.639W" | 21.883756 | -102.357122 | 1861 | F13D18 | 41 | 24 | 17 | 12 |
| 3 | 10010100 | 1 | Aguascalientes | Ags. | 1 | Aguascalientes | 100 | Rancho Alegre | R | 21°51´16.556N" | 102°22´21.884W" | 21.854599 | -102.372746 | 1879 | F13D18 | 0 | 0 | 0 | 0 |
| 4 | 10010102 | 1 | Aguascalientes | Ags. | 1 | Aguascalientes | 102 | Los Arbolitos [Rancho] | R | 21°46´48.650N" | 102°21´26.261W" | 21.780181 | -102.357295 | 1861 | F13D18 | 8 | * | * | 2 |
Verás que nuestro nuevo conjunto de datos contiene 300,083 filas y 19 columnas. Además de los datos correspondientes a las coordenadas geográficas tenemos otros datos como la altitud, el total de población (total y por sexos), el total de viviendas habitadas, entre otros datos relacionados con claves de entidades.
Tenemos como dato común los municipios de residencia de los casos por Covid y el nombre del municipio (Nom_Mun) de los datos del INEGI. Ya que aprendimos a renombrar las columnas, aprovechemos para renombrar las columnas de las coordenadas de tal manera que podamos crear una columna común sobre la cual hacer la unión.
areas_inegi.rename(
columns={'Nom_Mun':'municipio_residencia'}, # recordemos que cambiamos el nombre de la columna en el ejercicio anterior
inplace=True)
areas_inegi.head()
| Mapa | Cve_Ent | Nom_Ent | Nom_Abr | Cve_Mun | municipio_residencia | Cve_Loc | Nom_Loc | Ámbito | Latitud | Longitud | Lat_Decimal | Lon_Decimal | Altitud | Cve_Carta | Pob_Total | Pob_Masculina | Pob_Femenina | Total De Viviendas Habitadas | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 10010001 | 1 | Aguascalientes | Ags. | 1 | Aguascalientes | 1 | Aguascalientes | U | 21°52´47.362N" | 102°17´45.768W" | 21.879823 | -102.296047 | 1878 | F13D19 | 863893 | 419168 | 444725 | 246259 |
| 1 | 10010094 | 1 | Aguascalientes | Ags. | 1 | Aguascalientes | 94 | Granja Adelita | R | 21°52´18.749N" | 102°22´24.710W" | 21.871875 | -102.373531 | 1901 | F13D18 | 5 | * | * | 2 |
| 2 | 10010096 | 1 | Aguascalientes | Ags. | 1 | Aguascalientes | 96 | Agua Azul | R | 21°53´01.522N" | 102°21´25.639W" | 21.883756 | -102.357122 | 1861 | F13D18 | 41 | 24 | 17 | 12 |
| 3 | 10010100 | 1 | Aguascalientes | Ags. | 1 | Aguascalientes | 100 | Rancho Alegre | R | 21°51´16.556N" | 102°22´21.884W" | 21.854599 | -102.372746 | 1879 | F13D18 | 0 | 0 | 0 | 0 |
| 4 | 10010102 | 1 | Aguascalientes | Ags. | 1 | Aguascalientes | 102 | Los Arbolitos [Rancho] | R | 21°46´48.650N" | 102°21´26.261W" | 21.780181 | -102.357295 | 1861 | F13D18 | 8 | * | * | 2 |
Ahora sí podremos empezar a “jugar” con nuestros datos para lograr un conjunto de datos con la información de geolocalización.
“Inner” merge#
De manera predeterminada, pandas combina nuestros datos con una unión “inner”, es decir, que encuentra la información común de ambos conjuntos de datos y excluye la que no está en ambos. Podemos representar lo anterior a través de este diagrama de Venn:
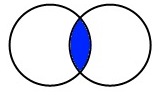
Para hacer la unión de nuestros datos usaremos la siguiente sintaxis:
pd.merge(left, right, how='inner')
Lo cual se traduce en:
inner_merge = pd.merge(covid_nacional, areas_inegi, how='inner', on='municipio_residencia')
inner_merge.head()
| Unnamed: 0 | fecha_actualizacion | id_registro | origen | sector | entidad_um | sexo | entidad_nacimiento | entidad_residencia | municipio_residencia | ... | Latitud | Longitud | Lat_Decimal | Lon_Decimal | Altitud | Cve_Carta | Pob_Total | Pob_Masculina | Pob_Femenina | Total De Viviendas Habitadas |
|---|
0 rows × 59 columns
Pero ¡este no es el resultado que esperábamos! ¿Por qué nos regresa una tabla vacía pero con 59 columnas?
Esto es fácil de identificar: pandas no encuentra datos comunes porque la información del conjunto de datos de covid_nacional está escrito en mayúsculas sostenidas y la información del conjunto de datos de areas_inegi está escrito en mayúsculas y minúsculas. Más adelante veremos con mayor detalle como “normalizar” nuestros datos para evitar estas inconsistencias.
Por lo pronto, podemos transformar nuestros datos a minúsculas en la columna municipio_residencia tanto en covid_nacional como en areas_inegi para que podamos hacer la unión. Afortunadamente, ambos conjuntos de datos conservan la acentuación gráfica de los datos, lo que nos facilita su unificación.
covid_nacional['municipio_residencia'] = covid_nacional['municipio_residencia'].str.lower()
areas_inegi['municipio_residencia'] = areas_inegi['municipio_residencia'].str.lower()
Ahora, apliquemos nuevamente la unión a nuestro conjunto de datos. Pero primero, vamos a reducir nuestro conjunto de datos para hacerlo más manejable.
¿Por qué reducimos los datos?
Al experimentar con grandes conjuntos de datos es altamente recomendable ser amable con los recursos computacionales. Si hacemos estos ejercicios directamente con todo el conjunto de datos nos tomará más tiempo y estaremos expuestos a errores de memoria.
covid_nacional_tm = covid_nacional[:100] # reducimos el conjunto de datos a 100 filas
inner_merge = pd.merge(covid_nacional_tm, areas_inegi, how='inner', on='municipio_residencia')
print(inner_merge.shape)
inner_merge.head()
(624, 59)
| Unnamed: 0 | fecha_actualizacion | id_registro | origen | sector | entidad_um | sexo | entidad_nacimiento | entidad_residencia | municipio_residencia | ... | Latitud | Longitud | Lat_Decimal | Lon_Decimal | Altitud | Cve_Carta | Pob_Total | Pob_Masculina | Pob_Femenina | Total De Viviendas Habitadas | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 8 | 2022-06-26 | 0ba73d | FUERA DE USMER | ISSSTE | CIUDAD DE MÉXICO | MUJER | QUERÉTARO | MÉXICO | naucalpan de juárez | ... | 19°28´43.690N" | 099°13´59.585W" | 19.478803 | -99.233218 | 2280 | E14A39 | 776220 | 373698 | 402522 | 225509 |
| 1 | 8 | 2022-06-26 | 0ba73d | FUERA DE USMER | ISSSTE | CIUDAD DE MÉXICO | MUJER | QUERÉTARO | MÉXICO | naucalpan de juárez | ... | 19°26´28.806N" | 099°20´21.556W" | 19.441335 | -99.339321 | 2846 | E14A38 | 9920 | 4802 | 5118 | 2404 |
| 2 | 8 | 2022-06-26 | 0ba73d | FUERA DE USMER | ISSSTE | CIUDAD DE MÉXICO | MUJER | QUERÉTARO | MÉXICO | naucalpan de juárez | ... | 19°28´32.024N" | 099°20´39.833W" | 19.475562 | -99.344398 | 2738 | E14A38 | 3595 | 1773 | 1822 | 942 |
| 3 | 8 | 2022-06-26 | 0ba73d | FUERA DE USMER | ISSSTE | CIUDAD DE MÉXICO | MUJER | QUERÉTARO | MÉXICO | naucalpan de juárez | ... | 19°26´21.138N" | 099°22´38.200W" | 19.439205 | -99.377278 | 3298 | E14A38 | 50 | 28 | 22 | 21 |
| 4 | 8 | 2022-06-26 | 0ba73d | FUERA DE USMER | ISSSTE | CIUDAD DE MÉXICO | MUJER | QUERÉTARO | MÉXICO | naucalpan de juárez | ... | 19°29´44.683N" | 099°18´19.417W" | 19.495745 | -99.305394 | 2501 | E14A39 | 1013 | 490 | 523 | 255 |
5 rows × 59 columns
Ahora estamos enfrentándonos a otro problema: ¡el resultado de la unión son 624 filas! ¿Por qué? Esto se debe a que los datos de municipio_residencia no están asociados con un campo único. Esto lo podemos ver aquí:
areas_inegi.loc[areas_inegi['municipio_residencia'] == 'chalco']
| Mapa | Cve_Ent | Nom_Ent | Nom_Abr | Cve_Mun | municipio_residencia | Cve_Loc | Nom_Loc | Ámbito | Latitud | Longitud | Lat_Decimal | Lon_Decimal | Altitud | Cve_Carta | Pob_Total | Pob_Masculina | Pob_Femenina | Total De Viviendas Habitadas | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 140805 | 150250001 | 15 | México | Mex. | 25 | chalco | 1 | Chalco de Díaz Covarrubias | U | 19°15´40.074N" | 098°53´44.357W" | 19.261132 | -98.895655 | 2238 | E14B31 | 174704 | 83207 | 91497 | 45578 |
| 140806 | 150250002 | 15 | México | Mex. | 25 | chalco | 2 | La Candelaria Tlapala | U | 19°14´26.710N" | 098°50´49.712W" | 19.240753 | -98.847142 | 2254 | E14B41 | 9446 | 4620 | 4826 | 2428 |
| 140807 | 150250005 | 15 | México | Mex. | 25 | chalco | 5 | San Gregorio Cuautzingo | U | 19°15´25.528N" | 098°51´29.893W" | 19.257091 | -98.858304 | 2244 | E14B31 | 8485 | 4109 | 4376 | 2134 |
| 140808 | 150250009 | 15 | México | Mex. | 25 | chalco | 9 | Instituto Damián (Ex-Hacienda San Juan de Dios) | R | 19°14´16.312N" | 098°54´32.585W" | 19.237864 | -98.909051 | 2241 | E14B41 | 1 | * | * | 1 |
| 140809 | 150250010 | 15 | México | Mex. | 25 | chalco | 10 | San Juan Tezompa | U | 19°12´25.717N" | 098°57´37.832W" | 19.207144 | -98.960509 | 2239 | E14B41 | 13127 | 6422 | 6705 | 3453 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 140872 | 150250147 | 15 | México | Mex. | 25 | chalco | 147 | Hacienda San Juan [Conjunto Urbano] | U | 19°16´08.352N" | 098°50´25.142W" | 19.268987 | -98.840317 | 2257 | E14B31 | 1623 | 774 | 849 | 458 |
| 140873 | 150250148 | 15 | México | Mex. | 25 | chalco | 148 | Villas de San Martín [Conjunto Urbano] | U | 19°16´03.967N" | 098°50´09.801W" | 19.267769 | -98.836056 | 2258 | E14B31 | 5714 | 2786 | 2928 | 1698 |
| 140874 | 150250149 | 15 | México | Mex. | 25 | chalco | 149 | Los Héroes Chalco [Conjunto Urbano] | U | 19°15´37.533N" | 098°50´29.037W" | 19.260426 | -98.841399 | 2253 | E14B31 | 34277 | 16552 | 17725 | 9965 |
| 140875 | 150250151 | 15 | México | Mex. | 25 | chalco | 151 | Valle Plateado [Fraccionamiento] | R | 19°13´06.312N" | 098°47´15.789W" | 19.218420 | -98.787719 | 2449 | E14B41 | 67 | 36 | 31 | 20 |
| 140876 | 150250152 | 15 | México | Mex. | 25 | chalco | 152 | La Pulida | R | 19°13´30.678N" | 098°49´25.945W" | 19.225188 | -98.823874 | 2292 | E14B41 | 154 | 68 | 86 | 39 |
72 rows × 19 columns
Al hacer el merge, el conjunto de datos se multiplica por las coincidencias, encontrándonos así con una tabla que nos da información inconsistente.
¡importante!
Un error común al hacer un merge es terminar con un conjunto de datos mucho mayor del esperado. Esto se debe a que provienen de fuentes diferentes y no se puede predecir con exactitud cuántos datos se obtendrán. Por esta razón es fundamental asegurarse de que el conjunto de datos resultante sea el esperado. Una manera práctica de hacerlo es valiéndose del módulo shape. Si el resultado es un número inconsistente (por ejemplo, que 100 casos de Covid se convirtieran en 624) debemos revisar dónde se encuentra el error.
Lastimosamente no existe una fórmula que abarque todos los casos, así que este es un paso que depende en buena medida de nuestra capacidad para detectar errores.
Tendremos finalmente que hacer una depuración de los datos de areas_inegi_tm para que coincida con nuestros datos. Encontramos que el registro de datos de covid_nacional usa como municipio_residencia el nombre principal del municipio, en este caso, coincide con la clave 1 del campo Cve_Loc en areas_inegi. Segmentaremos nuestro conjunto de datos valiéndonos del método .loc y podremos hacer nuevamente nuestro ‘inner merge’
# segmentamos nuestro conjunto de datos de areas_inegi
areas_inegi_tm = areas_inegi.loc[areas_inegi['Cve_Loc'] == 1]
# realizamos nuestro merge
inner_merge = pd.merge(covid_nacional_tm, areas_inegi_tm, how='inner', on='municipio_residencia')
print(inner_merge.shape)
inner_merge.head()
(15, 59)
| Unnamed: 0 | fecha_actualizacion | id_registro | origen | sector | entidad_um | sexo | entidad_nacimiento | entidad_residencia | municipio_residencia | ... | Latitud | Longitud | Lat_Decimal | Lon_Decimal | Altitud | Cve_Carta | Pob_Total | Pob_Masculina | Pob_Femenina | Total De Viviendas Habitadas | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 8 | 2022-06-26 | 0ba73d | FUERA DE USMER | ISSSTE | CIUDAD DE MÉXICO | MUJER | QUERÉTARO | MÉXICO | naucalpan de juárez | ... | 19°28´43.690N" | 099°13´59.585W" | 19.478803 | -99.233218 | 2280 | E14A39 | 776220 | 373698 | 402522 | 225509 |
| 1 | 11 | 2022-06-26 | 04fc18 | FUERA DE USMER | SEDENA | CIUDAD DE MÉXICO | HOMBRE | CIUDAD DE MÉXICO | MÉXICO | atizapán | ... | 19°10´36.328N" | 099°29´16.591W" | 19.176758 | -99.487942 | 2590 | E14A48 | 10873 | 5250 | 5623 | 2342 |
| 2 | 24 | 2022-06-26 | 3a5f83 | FUERA DE USMER | SSA | CIUDAD DE MÉXICO | MUJER | CIUDAD DE MÉXICO | MÉXICO | zumpango | ... | 19°47´49.643N" | 099°06´02.282W" | 19.797123 | -99.100634 | 2261 | E14A19 | 53362 | 26058 | 27304 | 13659 |
| 3 | 25 | 2022-06-26 | 3d59ea | FUERA DE USMER | SSA | CIUDAD DE MÉXICO | MUJER | GUERRERO | MÉXICO | zumpango | ... | 19°47´49.643N" | 099°06´02.282W" | 19.797123 | -99.100634 | 2261 | E14A19 | 53362 | 26058 | 27304 | 13659 |
| 4 | 26 | 2022-06-26 | 284743 | USMER | ISSSTE | CIUDAD DE MÉXICO | MUJER | CIUDAD DE MÉXICO | MÉXICO | nezahualcóyotl | ... | 19°24´31.548N" | 099°01´05.520W" | 19.408763 | -99.018200 | 2262 | E14A39 | 1072676 | 515678 | 556998 | 297975 |
5 rows × 59 columns
¡Eureka! Tenemos una tabla con el resultado esperado. ¿Cómo lo sabemos? (15 filas parece un número sospechoso) Porque coincide con el número de valores no nulos que nos regresa la columna municipio_residencia en covid_nacional_tm.
covid_nacional_tm['municipio_residencia'].value_counts()
nezahualcóyotl 5
zumpango 2
chalco 2
naucalpan de juárez 1
atizapán 1
atlautla 1
ciudad fernández 1
ecatepec de morelos 1
huixquilucan 1
Name: municipio_residencia, dtype: int64
Outer Merge#
La unión “hacia afuera” es todo lo contrario a un “inner merge”. En este caso, combinamos todos los campos de covid_nacional con todos los campos de areas_inegi, incluyendo aquellos que no coincidan. Así lo vemos en un diagrama de Venn:
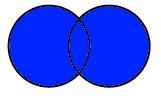
Apliquemos un “outer merge” a nuestro ejemplo anterior para ver los resultados:
outer_merge = pd.merge(covid_nacional_tm, areas_inegi_tm, how='outer', on='municipio_residencia')
print(outer_merge.shape)
outer_merge.head()
(2564, 59)
| Unnamed: 0 | fecha_actualizacion | id_registro | origen | sector | entidad_um | sexo | entidad_nacimiento | entidad_residencia | municipio_residencia | ... | Latitud | Longitud | Lat_Decimal | Lon_Decimal | Altitud | Cve_Carta | Pob_Total | Pob_Masculina | Pob_Femenina | Total De Viviendas Habitadas | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 2022-06-26 | 0793b8 | FUERA DE USMER | SSA | CIUDAD DE MÉXICO | HOMBRE | CIUDAD DE MÉXICO | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 2.0 | 2022-06-26 | 0fef08 | USMER | SSA | CIUDAD DE MÉXICO | HOMBRE | CIUDAD DE MÉXICO | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 3.0 | 2022-06-26 | 11e31a | FUERA DE USMER | SSA | CIUDAD DE MÉXICO | HOMBRE | CIUDAD DE MÉXICO | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 4.0 | 2022-06-26 | 0741e4 | FUERA DE USMER | ISSSTE | CIUDAD DE MÉXICO | HOMBRE | CIUDAD DE MÉXICO | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 5.0 | 2022-06-26 | 13c92b | FUERA DE USMER | SSA | CIUDAD DE MÉXICO | MUJER | CIUDAD DE MÉXICO | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
5 rows × 59 columns
Vemos que el resultado son 2,564 filas. Es una cantidad bastante grande, pero no es un error. Lo que sucede en este caso, es que se combinan los datos que coincide con los valores de municipio_residencia y se combinan los datos que no coinciden. Donde no hay coincidencias, las celdas se llenan con valores nulos.
Para nuestro ejemplo, una unión hacia afuera no es útil. Pero supongamos que tenemos un conjunto de datos de estudiantes con las calificaciones del primer trimestre:
estudiantes_trimestre1 = pd.DataFrame(
{'Nombre': ["Andrea", "Berenice", "Carlos"],
'Calificaciones_T1': [10, 8, 9]})
estudiantes_trimestre1
| Nombre | Calificaciones_T1 | |
|---|---|---|
| 0 | Andrea | 10 |
| 1 | Berenice | 8 |
| 2 | Carlos | 9 |
Ahora, queremos agregar las calificaciones de otro conjunto de datos correspondiente al segundo trimestre:
estudiantes_trimestre2 = pd.DataFrame(
{'Nombre': ["Andrea", "Berenice", "Carlos"],
'Calificaciones_T2': [9, 7, 8]})
estudiantes_trimestre2
| Nombre | Calificaciones_T2 | |
|---|---|---|
| 0 | Andrea | 9 |
| 1 | Berenice | 7 |
| 2 | Carlos | 8 |
En este caso, un ‘outer merge’ es indicado:
outer_merge = pd.merge(estudiantes_trimestre1, estudiantes_trimestre2, how='outer', on='Nombre')
outer_merge
| Nombre | Calificaciones_T1 | Calificaciones_T2 | |
|---|---|---|---|
| 0 | Andrea | 10 | 9 |
| 1 | Berenice | 8 | 7 |
| 2 | Carlos | 9 | 8 |
A modo de cierre#
Es necesario que selecciones tu método de unión de acuerdo a la lógica de tus datos. Revisa los resultados de tus combinaciones y ajusta los datos para que lleguen al resultado esperado. En ocasiones esto no es un proceso simple, tienes que reducir los datos y hacerlos manejables para que sea mucho más sencillo llegar a encontrar el error. Todas estas son prácticas que debes tener en cuenta y que no dependen del lenguaje de programación que estes utilizando.
Para saber más#
Existen otros métodos de unión de conjuntos de datos como el ‘left merge’ y el ‘right merge’, el método ‘join’ o la concatenación (‘concat’). Para no extendernos más, quisiera sugerirles el capítulo 2 del libro de [Stepanek and John, 2020] donde se explica de manera sintética cómo utilizar estos métodos.